时间:2025-10-31 来源:FPGA_UCY 关于我们 0
来自“XPU:AI时代与异构计算(AI算力篇)”,所有资料都已上传至“智能计算芯知识星球”星球异构计算技术专栏(搜索“异构计算”下载)。
ASIC,Application Specific Integrated Circuit,即专用集成电路芯片,是一种为了专门目的或算法而设计的芯片。
ASIC 芯 片 的 架 构 并 不 固定, 既 有 较 为 简 单 的 网 卡 芯片,用于控制网络流量,满足防火墙需求等,也有类似于谷歌TPU 等的顶尖AI 芯片。只要是为了某一类算法或某一类用户需求而去专门设计的芯片,都可以称之为ASIC。
相比能够运行各种应用程序的GPU 和能够在制造后重新编程以执行不同任务的FPGA,ASIC 需要定制设计,灵活性较差。但由于ASIC 是为了某一类需求和算法而设计的芯片,因此其在特定应用中表现出色,性能明显优于其他芯片。
2023 年,数据中心定制加速 计 算 芯 片(ASIC) 规 模 约66 亿 美 元, 在AI 加 速 计 算 芯片市场占有率较低,为16%。
业内预计,AI ASIC 芯片成长空间广阔,未来增速有望超过通 用 加 速 计 算 芯 片。Marvell称,2028 年 定 制 芯 片 规 模 有望 超400 亿 美 元,CAGR 达45%, 而 通 用 加 速 计 算 芯 片2028 年预计达到1716 亿美元市场规模,CAGR 为32%。
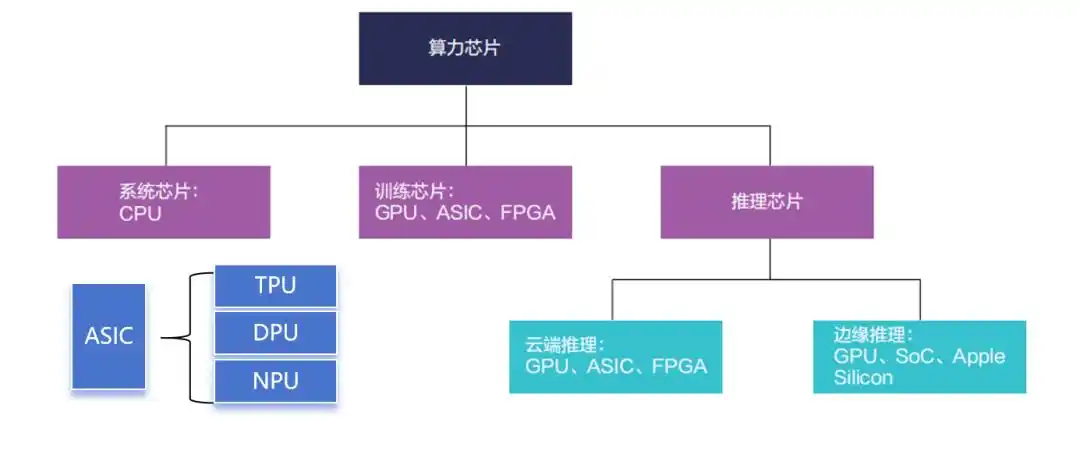
目前,ASIC芯片根据运算类 型 主 要 分 为TPU、DPU 和NPU,分别对应不同的基础计算功能。
1、TPU:谷歌定制,能效比突出
TPU 即 为 谷 歌 发 明 的AI处理器,主要支持张量计算,DPU 则是用于数据中心内部的加速计算,NPU 则是对应了上一 轮AI 热 潮 中 的CNN 神 经 卷积算法,后被大量集成进了边缘设备的处理芯片中。
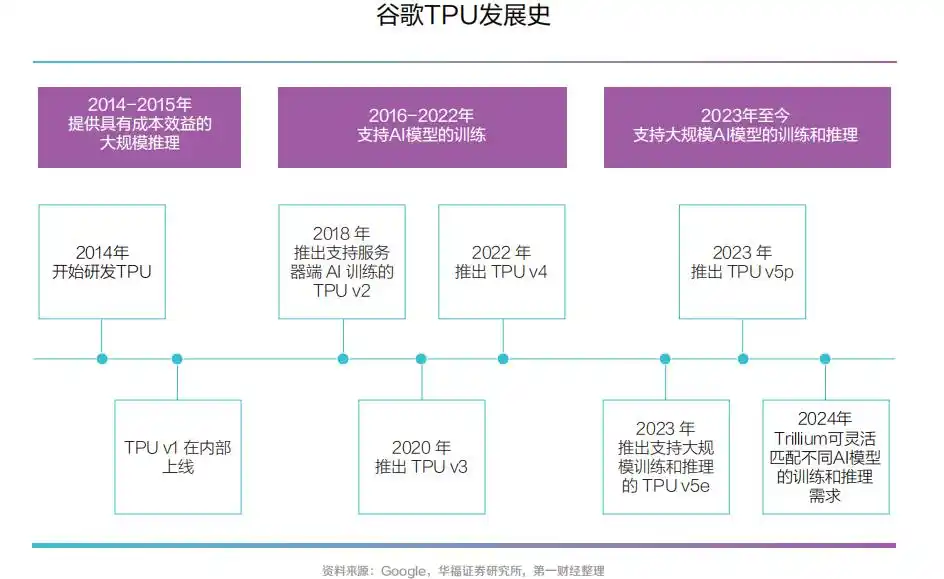
TPU, 即 张 量 处 理 单 元,属 于ASIC 的 一 种, 是 谷 歌 专门为加速深层神经网络运算能力而研发的一款芯片,为机器学习领域而定制。
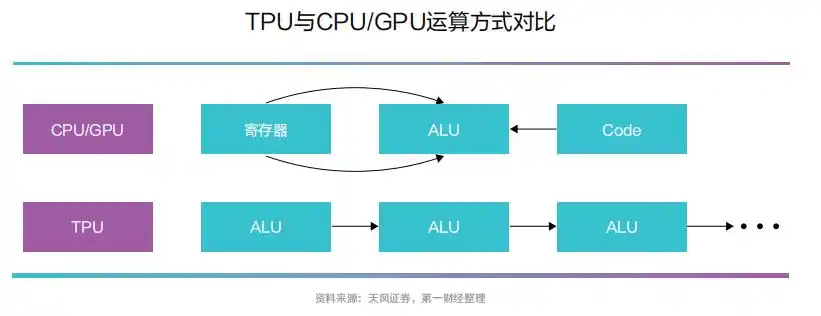
与传统CPU、GPU 架构不同,TPU 的MXU 设 计 采 用 了脉 动 阵 列(systolic array)架构,数据流动呈现出周期性的脉冲模式,类似于心脏跳动的供血方式。
CPU 与GPU 在 每 次 运 算中需要从多个寄存器中进行存取;而TPU 的脉动阵列将多个ALU 串联在一起,复用从一个寄存器中读取的结果。
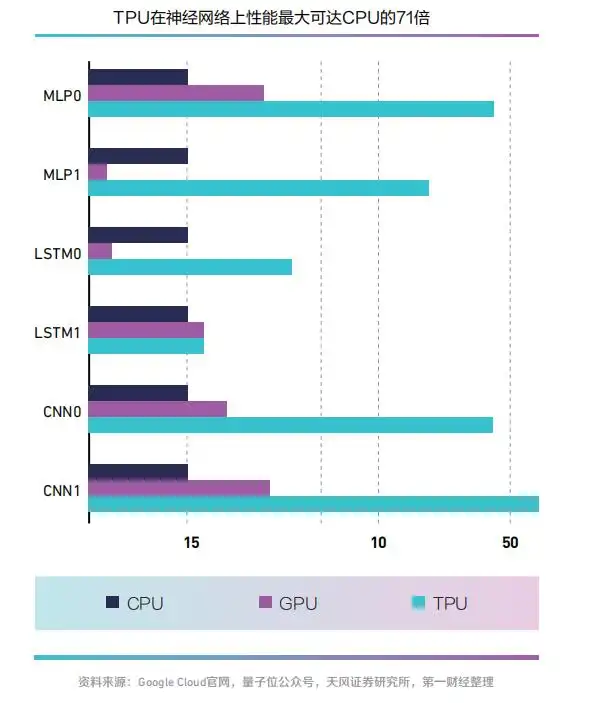
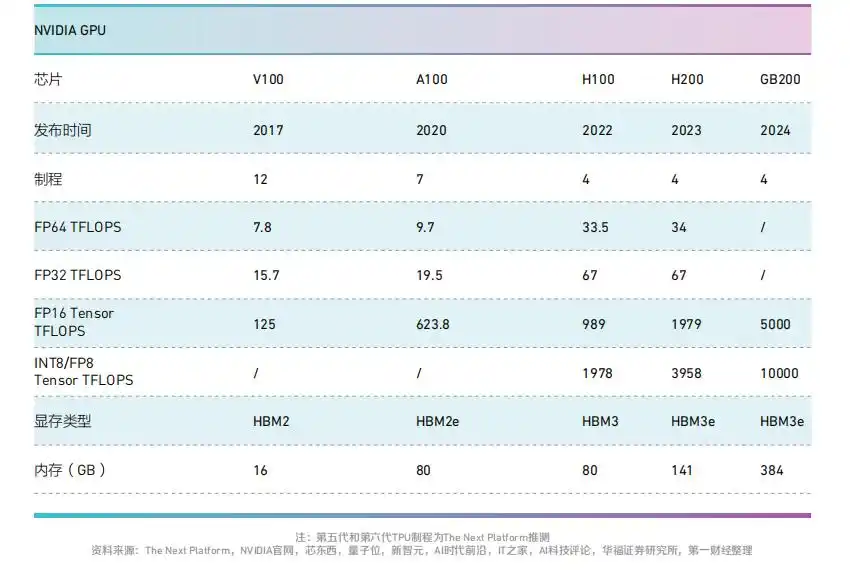
相比于CPU、GPU,TPU 在机器学习任务中因高能效 脱 颖 而 出, 其 中TPU v1 在神经网络性能上最大可达同时期CPU 的71 倍、GPU 的2.7倍。
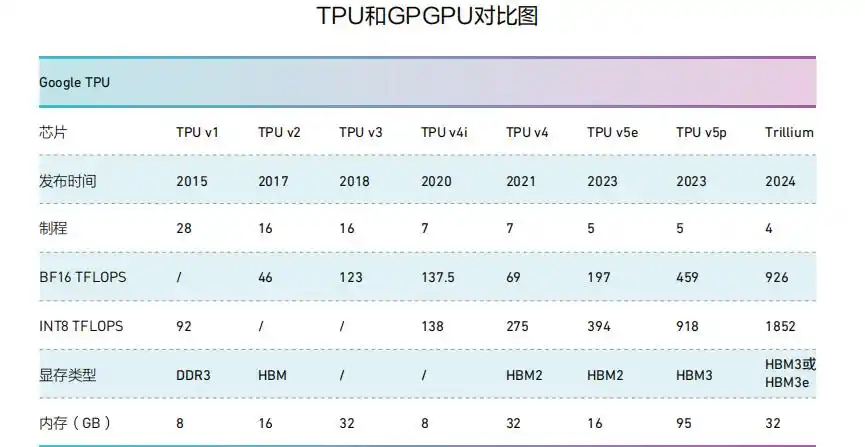
华福证券认 为,与 英 伟 达GPU 相 比, 在 算 力 上, 谷 歌TPU 目前暂时落后一代,在性能功耗比上谷歌优势显著。根 据Capvision, 谷 歌TPU70%-80% 的算力用于内部 业 务 场 景 使 用, 剩 余20%-30% 以租赁方式供外部使用。
随着TPUv4 于2021 年推出和大型语言模型的出现,谷歌芯片业务的规模显著增加,2023年TPU出货量已突破200 万颗量级。
2、DPU:CPU 和 GPU之后的“第三颗主力芯片”
DPU, 即 数 据 处 理 器,具备强大网络处理能力,以及安全、存储与网络卸载功能,可 释 放CPU 算 力, 能 够 完 成CPU 所 不 擅 长 的 网 络 协 议 处理、 数 据 加 解 密、 数 据 压 缩等数据处理任务,并对各类资源分别管理、扩容、调度,实现数据中心降本提效。即处理“CPU 做不好,GPU 做不了”的任务。
2020 年, 英 伟 达 发 布 的DPU 产品战略中将其定位为数据 中 心 继CPU 和GPU 之 后 的“第三颗主力芯片”,自此引爆了DPU 概念。
如今,DPU 已成为数据中心内新兴的专用处理器,专门设计用于加速数据中心中的安全、网络和存储任务,针对高带宽、低延迟的数据密集型计算场景提供动力。DPU 的核心作用是接管原本由CPU 处理的网络、存储、安全和管理等任务,从而释放CPU 资源,并加强数据安全与隐私保护。
作 为CPU 的 卸 载 引 擎,DPU 最直接的作用是接管网络虚拟化、硬件资源池化等基础设施层服务,释放CPU 的算力到上层应用,因此能够有效释放智算中心的算力,提升能效比 。
在 数 据 量 爆 炸 的AI 时 代,DPU 不仅能够协助构建兼具低时延、大带宽、高速数据通路的新型算力底座,还能够安全高效地调度、管理、联通这些分 布 式CPU、GPU 资 源, 从而释放智算中心的有效算力。
因 此,DPU 的 部 署 能 够 减 少数据中心的一次性capex(资本 性 支 出) 投 入。Cisco( 思科)的数据显示,通过虚拟化技术,企业可以减少高达40%的服务器数量,同时提高资源利用率。
另一方面,DPU 通过专用硬件加速网络、安全和存储任务,提高了数据中心的能效。

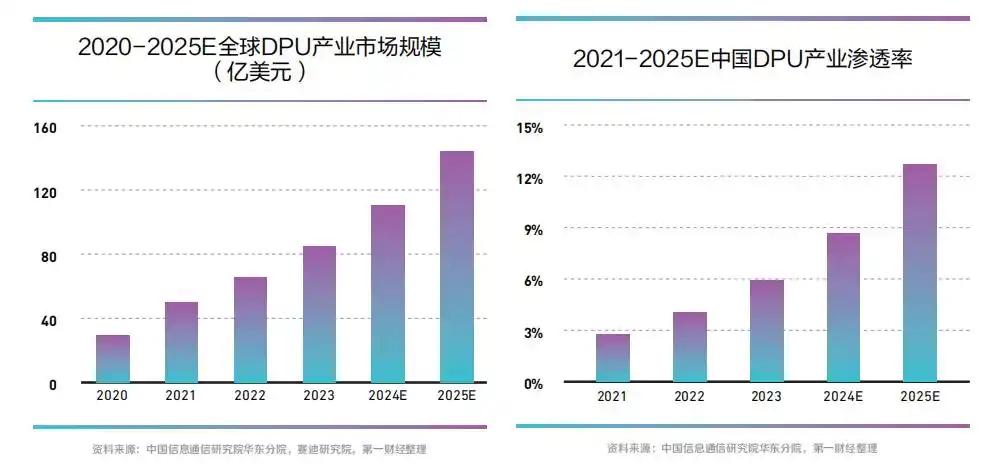
国内DPU 产 业 亦 蓄 势 待发,除了云厂商外,芯启源、中科驭数、星云智联、大禹智芯等企业纷纷入局。
3、NPU: 专 为 AI 应 用而生
NPU, 即 神 经 网 络 处 理单元,用于高效执行神经网络的计算,通常具有优化的硬件架构,如向量处理单元、矩阵乘法单元、卷积单元和激活函数单元等,能够在硬件级别上执行大规模矩阵运算和卷积运算, 以 提 高 神 经 网 络 计 算 效率 。
当 前 各 类AI 算 法 主 要 利用深度神经网络等算法模拟人类 神 经 元 和 突 触,NPU 能 够实现更高效率、更低能耗处理人 工 神 经 网 络、 随 机 森 林 等机器学习算法和深度学习模型。 如 今, 多 家 手 机 厂 商 已搭 载NPU,AIPC 也 将 通 过“CPU+NPU+GPU”打造本地混合计算。
NPU 采用“数据驱动并行计算”的架构,在电路层模拟人类神经元和突触,特别擅长处理视频、图像类的海量多媒体 数 据。 区 别 于CPU、GPU所遵循的冯诺依曼架构,NPU能够通过突触权重实现存储计算 一 体 化, 提 高 运 行 效 率,因 此 比GPU 更 擅 长 推 理。 且NPU 芯片设计逻辑更为简单,在处理推理工作负载时具有显著的能耗节约优势。
如 今, 大 模 型 已 进 入 轻 量化时代,端侧AI 应用正加速落地, 商 汤 曾 在2023 年年报中表示,2024 年将是端侧大模型应用的爆发之年。商汤联合创始人、首席科学家王晓刚解释称,成本、数据传输延迟、数据安全与隐私等几个重要问题,都可以通过端侧AI 或云端结合来解决。
与 云 侧 不 同 的 是, 端 侧 对于功耗更加敏感,对低功耗芯片的需求更明显。因此,随着人工智能应用场景陆续落地,NPU 易开发、高效能、低功耗等优势逐渐突显。业内普遍认为,在大算力需求爆发下,云侧的算力需求将传递至端侧。
目前,实现智能终端算力的最常用方式是在SoC 芯片中内置NPU 模块。相比于在云端用GPU 部署Transformer 大模型,在边缘侧、端侧部署Transformer 的最大挑战来自于功耗。因此在端侧和边缘侧,GPU 并非最合适的架构。

目 前, 国 内 芯 片 厂 商 正 奋力自研NPU,以迎接AI 浪潮。以阿里平头哥为代表的芯片公司已推出面向数据中心AI 应用的人工智能推理芯片,其NPU含光800 已成功应用在数据中心、边缘服务器等场景。
NPU IP 方 面, 芯 原 股 份2016 年 通 过对图芯美国的收购,获得了图形处理器(GPU)IP,在此基础 上 自 主 开 发 出 了NPU IP。
芯原股份此前告诉第一财经,目前,在AIoT 领域,公司用于人工智能的神经网络处理器IP已经被50 多家客户的100 多款芯片所采用,被用在物联网、可穿戴设备、安防监控、服务器、 汽 车 电 子 等10 个 应 用 领域 。
本文已分享完毕,本异构计算芯片系列分CPU篇、GPU篇、FPGA篇和ASIC篇(本文)四篇分享。