时间:2026-06-03 来源:FPGA_UCY 关于我们 0
我干了这么多年科技媒体,第一次看到硬件工程师们真的在紧张。不是担心裁员,是担心自己最值钱的手艺——手写Verilog代码,正在被AI抢走。
这事得从2026年5月下旬说起。那个月,FPGA领域悄悄发生了一场技术变革,RTL/Verilog/VHDL专用DSLM(特定领域语言模型)突然就成了FPGA开发的新"编译器"。说"突然"可能不太准确,因为这件事其实酝酿了好一阵子,但效果是爆炸性的——AI辅助代码生成从概念走向了大规模落地。
Gartner有个预测,到2028年,全球前十名AI供应商里头,会有一半推出面向硬件领域的专用AI模型。FPGA呢?正好是这场变革的核心战场。英伟达、AMD、Altera、Lattice这些全球头部厂商,最近纷纷公布了自己的FPGA AI战略。一场围绕"AI+FPGA代码生成"的技术军备竞赛,就这么打响了。
最有意思的信号来自黄仁勋。2026年3月GTC大会上,英伟达发布的Vera Rubin平台里,Groq 3 LPX推理加速机架居然把FPGA当成了标准配套协处理芯片。这意味着什么?意味着GPU时代的最大受益者,终于承认了AI推理需要异构计算这个现实。GPU负责高吞吐任务,FPGA负责更低延迟、更稳定响应的部分。黄仁勋没明说,但意思很明白:AI推理的未来,不是一种芯片赢全部,而是不同芯片各司其职。

那么,RTL DSLM到底是个啥?
说人话就是:它是专门用硬件设计语言(Verilog/VHDL)训练出来的大模型。你可以让它自动生成能用的Verilog/VHDL代码,它能修语法错误、修逻辑bug,还能自动帮你写testbench测试用例。更厉害的是,它真的能理解你的设计意图,然后给你面积、时延、功耗的优化建议。
你可以把它想象成在传统综合工具和时序分析工具上面,又叠了一层"AI智能编译器"。以前你得自己写RTL代码,现在你描述需求,它给你生成代码。开发周期从数周压缩到数小时,这不是量变,是质变。
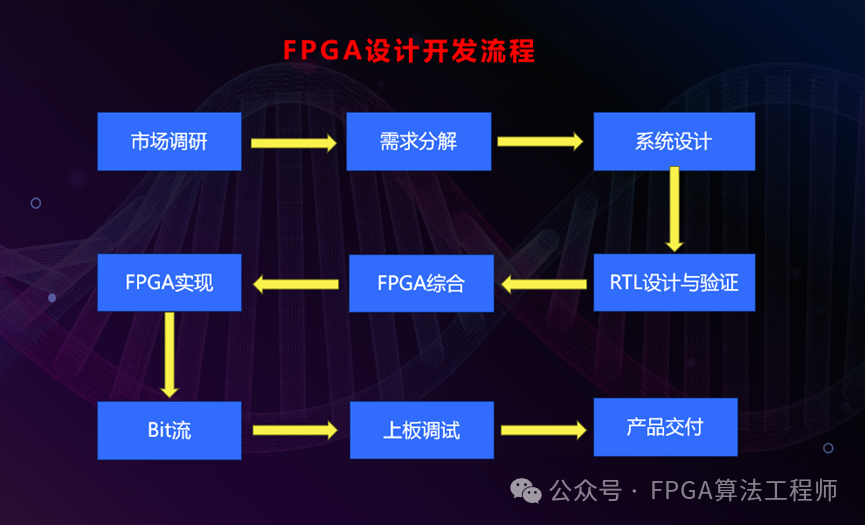
我跟你讲个细节。传统FPGA开发流程里,工程师要手写RTL代码,这活儿依赖经验丰富的硬件工程师,开发周期长,调试成本巨高,一个复杂模块可能要写数周。现在呢?工程师描述需求,AI自动生成RTL代码,开发周期从数周压缩到数小时。门槛也降低了,不是FPGA专家的人也能参与开发。这对行业的影响是深远的——它意味着FPGA开发可能要从"手工艺"变成"工业化生产"了。

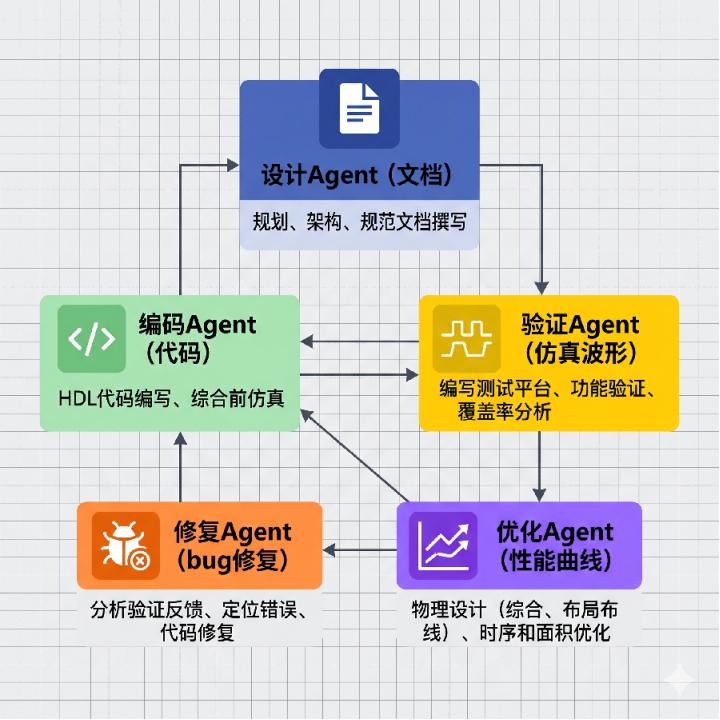
多智能体:FPGA开发的"流水线革命"
Gartner提了个概念叫"多智能体MAS",现在正在FPGA开发里落地。什么意思呢?就是把传统开发流程拆成多个AI智能体,每个负责一块:
设计Agent负责从自然语言规格自动生成模块和接口定义;编码Agent生成RTL代码、约束文件和综合脚本;验证Agent自动生成testbench并调用仿真器分析波形;修复Agent根据仿真报错自动修改代码;优化Agent结合设计手册和历史项目进行PPA(性能/功耗/面积)优化。
效果是什么?传统"多人多岗协作"变成了"多AI代理协作"。设计迭代周期压缩50%以上,人力成本大幅降低。你可以把它想象成一个AI团队,每个Agent负责一个环节,它们之间协作完成整个FPGA开发流程,而人类工程师只需要定义需求和做最终决策。这不就是工业革命的套路吗?把复杂手艺拆成简单工序,然后用机器替代人工。
hls4ml:让软件工程师也能玩FPGA
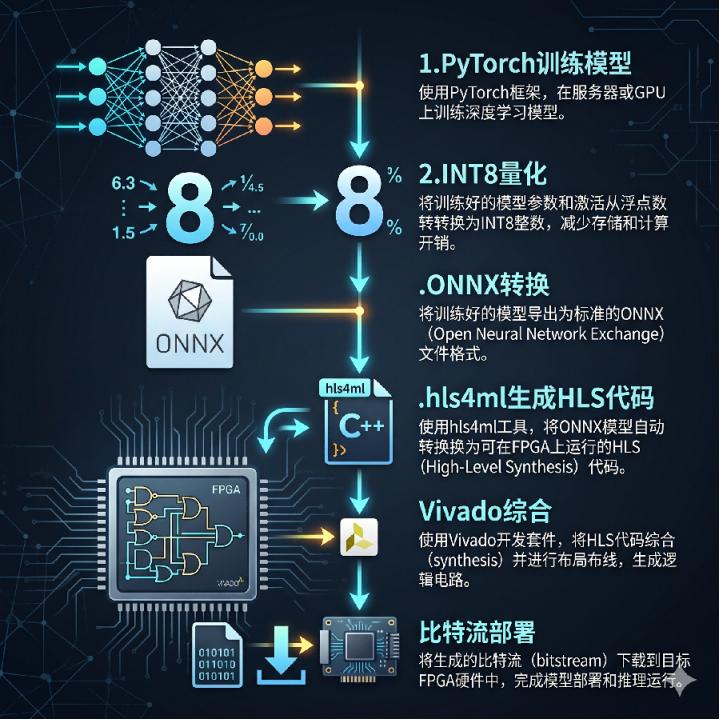
HLS工具链的AI升级是另一个大故事。hls4ml现在是公认最成熟的HLS AI代码生成开源工具,它能把PyTorch/Keras/ONNX模型直接转成HLS代码。这话什么意思?意思是软件工程师不用再学Verilog了,你用Python训练个模型,它帮你转成FPGA能跑的代码。
典型流程是这六步:PyTorch/TensorFlow训练模型→INT8量化处理→ONNX格式转换→hls4ml生成HLS代码→Vivado综合与实现→比特流生成并部署。听起来步骤不少,但比以前从零开始写RTL少了太多。
这里有个关键技术点:HLS优化四大指令。这是提升性能的核心,我给你掰扯掰扯:#pragma HLS PIPELINE是流水线化,让多周期操作并行执行;#pragma HLS UNROLL是循环展开,并行执行循环内操作;#pragma HLS ARRAY_PARTITION是数组分割,提高数据访问并行度;#pragma HLS DATAFLOW是数据流优化,让多模块并行工作。
有个实际案例能说明问题:YOLO目标检测加速器部署。从PyTorch导出YOLOv5/v8模型为ONNX,INT8量化后通过hls4ml生成HLS代码,Vivado综合实现后在FPGA上部署验证。实测性能:推理延迟50-100ms,吞吐量10-30fps,功耗5-20W。对比CPU方案,推理速度提升了45-75倍。这什么概念?原来需要服务器集群才能做的事,现在一块FPGA板子就搞定了。
三大厂商,三条路
现在全球FPGA市场基本上是AMD(收购了Xilinx)、Altera(被英特尔卖了又买回来)、Lattice这三家玩,它们的AI战略完全不一样。
AMD走的是"自适应计算平台"路线,代表产品是Versal AI Edge系列。它的逻辑是:我不只是卖你一块AI加速芯片,我给你的是面向自动驾驶、医疗、工厂等场景的"传感器接入+AI处理+实时控制"全链路平台。在AMD的愿景里,FPGA的定位从"跑模型"升级成了"感知-决策-控制"的系统底座。这个思路挺牛的,它把FPGA从配件变成了主角。
Altera走的是"工具链降门槛"路线,代表产品是FPGA AI Suite + OpenVINO生态。它的核心策略特别务实:降低模型部署到FPGA上的门槛。Altera有句话我很喜欢:"谁能让机器学习工程师、软件工程师和FPGA工程师更容易协同,谁就扩大客户规模"。在Altera看来,FPGA的定位是通过软件生态降低AI推理市场进入门槛,让更多人能用起来。这个思路跟AMD不一样,AMD是往上做平台,Altera是往下降门槛。
Lattice呢,走的是"低功耗边缘AI"路线,代表产品是sensAI低功耗FPGA系列。它专注边缘设备推理,追求低功耗、长续航。Lattice把FPGA定位为边缘AI推理的主力平台,这在物联网和移动设备日益增长的今天,是个挺聪明的选择。你想啊,边缘设备电池有限,FPGA比GPU省电多了。

英伟达的"投降声明"
回到英伟达。2026年3月GTC大会那个信号,我越想越觉得重要。英伟达Vera Rubin平台里,Groq 3 LPX推理加速机架采用FPGA作为标准配套协处理芯片。GPU负责高吞吐任务,LPX(基于FPGA/可编程逻辑)负责更低延迟、更稳定响应的部分。
英伟达官方表态:AI推理的未来不是一种芯片赢全部,不同芯片各司其职。这句话听起来很官方,但翻译成人话就是:我们GPU虽然牛,但搞不定所有场景,FPGA有它的地盘。
英伟达承认了什么现实?我给你列三条:第一,GPU适合训练,但推理市场需要异构计算。第二,FPGA在延迟敏感场景(工业控制、边缘推理)有不可替代优势。第三,GPU的灵活性不如FPGA——GPU硬件结构定型后无法改变,FPGA随时可重构。
第三条最致命。GPU一旦流片,架构就固定了。FPGA呢?今天跑视频接口转换,明天重新配置跑预处理逻辑,灵活性爆表。在AI算法还在快速迭代的现在,这个灵活性就是刚需。你总不能每次算法更新都重新流片吧?那成本谁扛得住?
为什么AI时代FPGA重新被看见了?
这事儿我琢磨很久了。FPGA其实不是新技术,它存在几十年了,但一直是个相对小众的领域。为什么AI时代它突然又被重视了?三个原因。
原因一:AI算法变化太快。GPU算力固定,ASIC一旦固化就没法适应算法演进。FPGA的可重构特性让它总能跟上最新算法。你想想,现在大模型架构几个月就变一次,你总不能每次都重新流片吧?FPGA不用,重新配置一下就行。
原因二:推理越靠近现场,场景越碎片化。工厂设备接工业相机、汽车接多路传感器、机器人处理运动控制。这些场景不只是"算一道题",还需要快速接入信号、处理并输出结果。GPU的通用架构在这些碎片化场景效率不高,就像用瑞士军刀切菜,能用,但不如菜刀顺手。
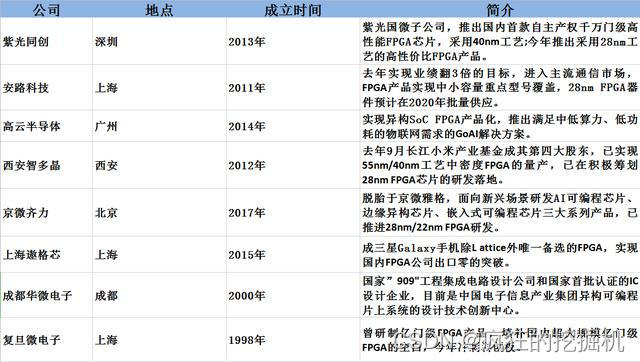
原因三:国产FPGA的差异化需求。安路科技的人跟我聊过,他们说不同服务器厂商、不同应用场景,对IO、电平、协议要求差异极大。固定ASIC很难覆盖所有设计,FPGA的可编程特性让少量型号就能适配多种方案。在国产替代背景下,FPGA的战略价值更加凸显,它不只是技术问题,更是供应链安全问题。
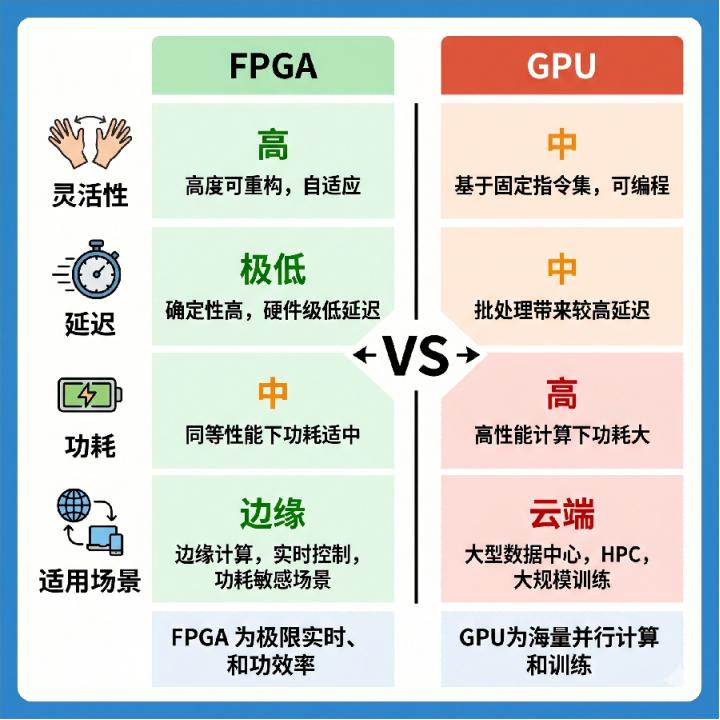
FPGA vs GPU:到底选谁?
这个问题现在被问得特别多。我给你个简单的选择指南:
选FPGA的场景:需要低延迟(
选GPU的场景:云端高吞吐、成熟生态、大批量固定任务。
具体来说,灵活性方面,FPGA高,随时可重构;GPU中,可运行不同软件;ASIC低,固化后不可改。开发门槛方面,FPGA高,需硬件工程能力;GPU低,CUDA生态成熟;ASIC高,需流片。推理延迟方面,FPGA极低(
普通人能得到什么好处?
你可能会问:这跟我有什么关系?关系大了。你用的AI推理应用背后,可能就是FPGA在跑。工业检测、自动驾驶、智能摄像头,都有FPGA的影子。
我给你举两个具体案例。案例一:YOLO目标检测加速器部署。前面提过了,对比CPU方案推理速度提升45-75倍,功耗只有5-20W。案例二:ResNet图像分类部署。优化策略是共享卷积计算单元、批量处理、内存访问优化。单张图像推理10-50ms,批量处理100+ fps,能效比>100 GOPS/W。这个能效比什么概念?就是说FPGA在省电这方面,真的把GPU按在地上摩擦。对于边缘设备来说,省电就是省钱,就是续航,就是竞争力。
硬件工程师会被取代吗?
最后回到这个灵魂拷问。AI会取代硬件工程师吗?我的看法是:不会完全取代,但会改变他们的工作方式。
以前硬件工程师要手写每一行RTL代码,现在可以让AI生成初稿,他们更多做审核、优化和架构设计。这就像建筑师不用自己搬砖了,但可以专注于设计更好的房子。那些只会重复性写代码的人可能会失业,但懂架构、懂优化、懂系统的人会更值钱。
这场变革才刚刚开始。Gartner预测到2028年,全球前十名AI供应商中将有一半推出面向硬件领域的专用AI模型。FPGA只是起点,未来可能有更多专用芯片和AI结合的场景。作为科技从业者或者投资者,现在就该关注这个领域了。作为普通人,了解这些技术趋势,也能帮你更好地理解这个快速变化的世界。
你看好FPGA在AI推理中的未来吗?觉得AI会取代硬件工程师吗?评论区聊聊你的看法!