时间:2025-12-26 来源:FPGA_UCY 关于我们 0
智能计算芯片概览
AI已成为全球经济和社会发展的重要驱动力。尤其是,LLMs将大幅推动AI向AGI的演进,而AGI有望在生产力和创造力方面从根本上改变人类社会。LLMs在AIGC、图像识别、内容推荐、销售预测、金融风险管理等方面迅速获广泛应用,预计将延伸至更多其他应用场景。根据灼识谘询的资料,预计至2030年,AI将推动全球国内生产总值的15%以上的增长。为实现AGI的愿景,急需计算芯片作为AGI落地的基础。

AI训练、推理和高性能计算等计算密集型任务,尤其是大规模的AI计算任务,主要在云端或边缘运行,涉及大量并行计算,即多项运算同时执行。智能计算芯片1正是为适应这些特性而专门设计,其架构适用于高速并行计算,主要包括三类芯片,即GPGPU(通用图形处理器)、ASIC(专用集成电路)及FPGA(现场可编程门阵列)。
事实证明,在执行计算密集型任务时,它们的效率大幅高于先前的计算芯片,例如CPU等专为串行计算设计、一次只能执行一个操作的计算芯片。唯有通过整合专业的软件生态系统,才能充分发挥智能计算芯片的潜力,为编程、编排和高效的工作负载分发提供必要的基础设施,使其成为智能计算芯片功能和实际应用中不可或缺的组件。自2012年(AI历史上具有里程碑意义的一年)以来,专门设计的计算芯片逐渐取代CPU,成为后来计算密集型任务的绝对选择。
全球智能计算芯片行业概览
训练与推理是两种主要的智能计算场景
训练和推理构成智能计算的核心应用场景。训练是指使用训练数据集创建模型的过程,而推理是指使用训练好的模型针对新数据输入返回预测结果的过程。过去三年,各种LLMs的开发及迭代在全球范围内蓬勃发展,预期此趋势近期将持续,从而推动对用于训练的计算能力的需求。
随著未来LLMs在功能和可用性方面的成熟,最终用例和频率将会显著增加,从长远来看,将导致对推理计算能力的需求增长更快。训练与推理在单一时段内的计算複杂度及频率方面具有明显的特点,因此两者对智能计算芯片的能力有不同要求。因此,应用于这两种不同场景的智能计算芯片通常会採用各自的设计和商业化策略。
随著模型参数规模的不断扩大和应用场景的複杂性不断提高,训练和推理对智能计算芯片的要求也越来越高,尤其是在计算能力、内存带宽和容量等方面。同时,行业正在从以预训练为核心的单阶段范式转变为并重后训练与推理的多阶段工作流程,这大大增加了对能够高效支持这两个阶段的芯片的需求。因此,训练和推理对芯片性能要求日益融合,推动了智能计算芯片架构向更集成、更通用的方向发展。
智能计算芯片行业正在经历并将继续增长
自2022年底推出的ChatGPT以来,LLMs的突破导致对智能计算芯片的需求快速增长。最初,需求主要集中在基础模型的训练,这些模型通常规模巨大,需要大量的算力才能完成训练。随著模型规模的进一步增加,按照缩放定律,对训练计算芯片的需求也呈指数级增长。随著模型架构的不断迭代,预训练和后训练的分化以及推理模型的引入已经从根本上改变了行业格局,导致训练和推理计算的市场需求同时增长。强化学习、微调和模型蒸馏等后训练过程现在需要比预训练更大的计算能力,从而放大了对训练计算芯片的需求。
同时,当前的推理模型应用了推理阶段扩展机制,使得每一次查询的计算能力比传统的一次性推理高出100倍,大幅增加了对推理计算芯片的需求。预计未来一两年内,对推理计算芯片的投资增长将超过训练。
以收入计,全球智能计算芯片市场从2020年的66亿美元快速增长至2024年的1,190亿美元,複合年增长率(“CAGR”)为106.0%。预计未来五年市场将保持快速增长,并于2029年达到5,857亿美元,2024年至2029年的CAGR为37.5%。有关增长将受到不久将来对AI计算基础设施(如AI数据中心)的投资激增的推动,以及长期内一系列基于LLM的AI应用有望蓬勃发展并持续消耗智能算力的驱动。
作为全球最大的AI市场之一,中国对智能计算芯片的需求亦快速增长。根据灼识谘询的资料,以收入计,中国智能计算芯片市场由2020年的17亿美元增长至2024年的301亿美元,CAGR为105%。预计到2029年,该市场将达到2,012亿美元,2024年至2029年的CAGR为46.3%,同期增长超过全球市场。这主要归因于需求的快速扩张、供应链本地化和生态系统的发展。儘管智能计算芯片的採用基数相对较低,中国正面临来自众多云服务供应商、网络平台、AI公司及其他AI驱动产业客户的庞大需求激增,由此形成可观的潜在市场规模与充裕的成长空间。同时,具有竞争力的国内供应商的崛起及生态系统的迅速成熟预期将支持未来智能计算芯片更快的部署及应用。
GPGPU是最通用的智能计算芯片
在三种智能计算芯片中,GPGPU为最通用的智能计算芯片。GPGPU基于非定制架构,可轻鬆应对多种计算任务。这在计算场景不断发展和多样化的当前景况下为关键优势。相比之下,ASIC通常为特定应用量身定制,而儘管FPGA可以重新配置以适应多种应用,但要求其用户精通硬件编码。儘管FPGA在其指定任务中具有出色的性能和能效,但其应用范围大幅小于GPGPU。因此,GPGPU已成为智能计算芯片的主流选择,并有望保持领先地位。下表载列三种智能计算芯片的优缺点。
GPGPU的下游客户主要包括大型互联网公司、云服务供应商、数据中心及AI公司,彼等依赖GPGPU来处理计算密集型工作负载,例如大型模型训练及推理,以及高效能计算。相较于专为特定或可程序化功能所设计的ASIC与FPGA,GPGPU具备更高的通用性与灵活性、高度平行处理能力,以及完善的软件生态系统,可有效满足不同AI模型架构与複杂通用任务对训练与推理日益增加的计算需求,成为智能计算芯片领域的主流解决方案。
GPGPU一直是全球智能计算芯片市场的主要部分,其市场规模于2024年佔整体智能计算芯片市场的92.0%。于2024年,中国GPGPU市场佔中国整体智能计算芯片市场的78.1%。儘管如此,中国GPGPU市场规模预期由2024年的235亿美元增加至2029年的1,723亿美元,CAGR为49.0%,较同期全球市场38.1%的CAGR更快。
软硬件的融合对智能计算芯片的性能至关重要
随著AI应用程序变得更加複杂和数据密集,对更高算力和更高效数据处理的需求不断增长。这需要在硬件设计方面不断改进和创新,以持续提供最佳性能和能效。其中,一个具有里程碑意义的架构演变的例子为引入专门硬件单元以处理矩阵乘法,矩阵乘法为在深度学习算法中常见的複杂计算,曾为提高AI计算速度的瓶颈之一。
此外,内存大小、带宽及互连的升级进一步增强了智能计算芯片(尤其是大规模集群)的能力,以有效处理繁重的工作负载。该等硬件迭代在增强智能计算芯片的能力方面发挥了基础作用。智能计算芯片以三种不同的形式提供予客户,以满足客户的需求,包括PCIe(外围组件高速互连)卡、OAM(开放式加速器模块)及服务器。
PCIe板卡是一种符合成本效益的选择,一般目标为需要平衡性能和成本的客户。OAM旨在优化性能,目标为需要最高性能的客户。服务器是即用型算力,面向需要在短时间内由零开始配备高算力的客户。服务器可以互连为超节点,并进一步扩展为服务器集群,提供大量计算资源以完成複杂且数量庞大的任务。
未来,服务器集群预期将在市场中扮演更重要的角色,以支持对大规模算力日益增长的需求,而部署单一服务器难以满足此需求。除硬件外,软件在优化智能计算芯片的性能方面发挥著至关重要的作用。其为开发人员提供了必要工具和通用深度学习框架,以充分利用底层硬件的功能。通过软件,开发人员可以进行重新配置,以最大限度地提高计算利用率,提高数据吞吐量,并确保稳健的多芯片互连性,以提高智能计算芯片的整体性能和效率。如今,允许开发人员灵活通过软件持续优化性能已成为智能计算芯片公司的关键竞争优势。
智能计算芯片价值链
智能计算芯片产业价值链以智能计算芯片供应商为中心,由于其直接影响芯片的性能,且需要深厚的工程技术及行业知识,因此至关重要。彼等不仅与多家提供支持及制造相关服务的供应商合作,以将其芯片交付最终用户,而且在引领整个行业进步方面发挥著重要作用。例如,顶级研发人员及工程师将利用他们的专业知识,与价值链参与者密切合作,共同开发技术和制造彼等的芯片,最终促进行业的技术进步。
支持服务供应商主要包括设计服务提供商、IP及EDA(电子设计自动化)工具提供商。设计服务供应商为芯片开发的各个阶段提供研发服务,并为后续制造及封装测试提供外包管理。IP供应商提供构建芯片所需的核心功能模块。EDA工具供应商提供用于芯片设计及验证的自动化软件工具,例如仿真器,它可以将芯片映射并置入一个虚拟环境中,该环境模拟了芯片设计的实际运行环境。实现芯片设计的制造过程包括四个主要阶段:芯片制造、芯片封装和测试、PCIe卡或OAM组装和测试,以及硬件系统集成。
智能计算芯片提供商向代工厂提供设计布局,代工厂据此制造芯片。芯片其后进行封装,以防止物理损坏及腐蚀。最后,芯片被组装到PCIe板卡、OAM中,然后集成为服务器,并进行功能和性能测试。
终端用户通常来自AI云服务、AI解决方案、能源及公用事业、金融科技及互联网等垂直行业。随著智能计算芯片的受众从少数行业先驱迅速普及至其他后来者,预计未来终端用户的覆盖范围将进一步扩大。
智能计算芯片的开发生命週期漫长且复杂
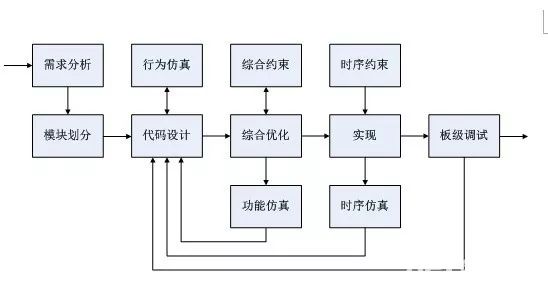
芯片设计过程漫长,且可分解为规格定义、架构设计、前端设计、物理设计、流片及流片后的验证。
规格定义:首先,芯片设计人员需要指定描述设计与其环境之间的所有接口的要求,其软硬件规格包括功能、硬件模块构成、接口、时序要求、性能及其他物理设计细节(如面积及功率)。
架构设计:架构设计在收集所有规格后进行。此步骤由行为及功能建模组成,明确芯片整体架构设计,包含组合逻辑模块、数据寄存器、总线、片上及片外存储器、交换单元及有限状态机等组件。可行性研究在此阶段进行,以评估不同的设计方案。
前端设计:确认架构后,将建立设计的高层次模型,并进行功能模拟和验证,以确保满足功能和性能目标。随后运用特定的软件工具,将设计进行集成并转换为门级网表,作为芯片逻辑结构的完整蓝图,标明所有逻辑单元及其连接方式。
物理设计:此过程将门级网表转换为物理布局,其中电路逻辑将映射到硅片上。物理设计过程中通常需要多轮优化与验证,以确保电气特性与逻辑功能正确,并满足制造工艺要求。
流片:芯片设计及验证后,一份载有芯片各层详细组成信息的文件将发送至代工厂,以进行制造、封装及测试。流片标志著芯片设计的关键里程碑,表明设计可以成功转化为实物产品,为芯片的最终商业化铺平道路。
流片后验证:制造完成后的芯片需在实际场景中经过严格测试,以识别任何需要修复的潜在错误或操作问题。进行流片后验证的目的是确保芯片符合所有要求,并在设计生命週期内的实际操作条件下正常运作,以便产品批量生产和销售。
中国智能计算芯片行业的市场驱动因素
AI在各行各业的商业化。近年来,AI已被广泛应用于各种垂直行业,如互联网、电信、制造、金融、政府及公用事业等。随著AI产品的性能和功能不断提升,企业越来越愿意投资AI应用以提高运营质量和效率。此外,AI亦已融入人们的日常生活,AI赋能的消费者导向型产品不断增加。作为AI应用的基础,对算力的需求亦势必增加,从而推动智能计算芯片的增长。云服务商(为智能计算芯片的最大消费者之一)的资本开支据称将于不久的将来飙升即为证明。
AI市场的蓬勃发展带来巨大的增量计算需求。AI技术的加速成熟和商业化正在推动对智能算力的需求大幅增长。随著AI产品从实验原型演变为大规模的实际应用,对训练及推理的计算需求已显著增长。自2022年以来,LLM蓬勃发展的初期,LLMs的预训练是智能计算芯片需求的主要来源。2024年,焦点从预训练转向后训练和多步逻辑推理,进一步与预训练一起刺激对智能计算芯片的需求。同时,AI应用的广泛部署对推理精度和即时响应能力提出了更高的要求。这些性能预期导致各种部署环境中的推理工作负载日益繁重。对训练及推理计算能力的需求将维持高位,持续带动智能计算芯片市场。
科技进步。架构、制程节点、封装及软件等技术的进步支撑著智能计算芯片的发展。架构设计与制程节点的升级相辅相成,对提供算力、能效及互连性最佳的最新芯片至关重要。先进的封装技术实现了创新设计理念(如芯粒),可有效解决芯片物理限制带来的挑战,并在成本、良率及设计灵活性方面表现出显著优势。完善的软件生态系统包括易于使用的配置工具和最新框架,确保应用程序可以在最新硬件上高效执行。
政策利好。过去十年来,中国政府高度重视并坚定支持中国AI产业发展,其被视为中国保持其在世界技术进步中的领先地位的最具战略意义的产业之一。同时,政府也通过资本投资、政策激励及其他方式,对作为AI部署基础设施的智能计算芯片行业给予大力支持。这些支持措施为中国AI及智能计算芯片行业蓬勃发展提供有力保证及指引,同时推动相关技术的竞争力及影响力持续提升。
中国智能计算芯片行业的市场趋势
智能计算芯片的本土化。在美国出口管制下,中国公司在向海外供应商採购高性能智能计算芯片以及与中国内地以外的合作伙伴(如代工厂、组装和测试制造服务提供商、IP和EDA供应商等)合作方面面临限制。儘管该等限制可能对中国智能计算芯片的整体供应构成短期挑战,但亦为中国发展独立的智能计算芯片行业带来机遇。通过升级技术和提升制造能力,中国正在见证芯片设计和制造的本土化,长远而言,这一趋势有望塑造中国智能计算芯片行业的未来。
端到端解决方案的需求不断增加。除硬件交付外,端到端智能计算芯片公司亦提供整套产品和服务,包括软件开发平台、NRE开发、部署及其他服务,这使其成为缺乏AI开发能力的客户的首选。随著智能计算芯片的普及,越来越多的客户青睐快速且实用的即用型端到端智能计算解决方案。
自主开发的软件生态系统。自主开发的软件生态系统为智能计算芯片公司构成强大的竞争壁垒,乃由于(i)彼等可通过重新配置,尽可能发挥底层硬件的性能潜力、(ii)彼等与合作伙伴(如客户、研究机构和开发人员)建立充满活力且不断丰富的生态系统,并为特定应用程序提供大量有用的库、工具、框架和定制资源,以上均吸引更多开发人员和贡献者。市场的新进入者通常会提供与现有参与者兼容的软件。然而,随著其自主开发生态系统的持续发展,预期其将逐步减少对现有生态系统的依赖并实现长期替代。由于上述原因,中国智能计算芯片提供商建立自有软件生态系统已变得越加重要且成为长期趋势。
异构计算。中国正日益需要从完全依赖进口智能计算芯片转向广泛採用国内芯片。在此过渡阶段,异构计算(如异构GPU协同训练或推理)通过将来自不同供应商的不同芯片集成到一个优化性能和能效的架构中发挥著至关重要的作用。这种方法不仅有助于从依赖外国技术无缝过渡到自主技术,亦可推动创新,使中国能够满足现代应用不断变化的需求,同时确保其智能计算芯片生态系统的稳定性及连续性。
更多行业研究分析请参考思瀚产业研究院官网,同时思瀚产业研究院亦提供行研报告、可研报告(立项审批备案、银行贷款、投资决策、集团上会)、产业规划、园区规划、商业计划书(股权融资、招商合资、内部决策)、专项调研、建筑设计、境外投资报告等相关咨询服务方案。
下一篇:芯片行业之浅谈FPGA芯片