时间:2026-05-27 来源:FPGA_UCY 关于我们 0
从边缘推理落地的实际需求来看,FPGA直接补上了GPU的低功耗低延迟短板

FPGA功耗仅为GPU的1/10,智能摄像头采用FPGA方案后,人脸识别功耗直接降至传统GPU方案的十分之一,在工业视觉检测场景里端到端延迟缩短30%-50%,工业色选机的误判率直接下降40%,启动速度最快达到5毫秒,比常规GPU服务器快12倍。
之前GPU想要部署到工业现场、户外机器人、智能交通这类边缘节点,往往受限于供电能力和散热条件,根本没法长时间稳定运行,现在FPGA作为前端协处理单元,把预处理、实时响应的活全部接走,GPU只需要在云端处理核心复杂计算,工业场景客户实际落地后年运维成本可以节省20%以上,次品率明显降低。
从大规模智能体推理的效率优化维度观察,FPGA解决了GPU算力空转的长期痛点
FPGA协处理可以让智能体的首次响应速度提升50%,百万token级的长上下文推理成本直接降至纯GPU方案的1%,还能通过固件优化协调单GPU并行运行数千个微调模型,硬件资源利用率提升20%以上。
比如腾讯Hy3智能体案例里,加入低延迟协处理后任务平均完成时间缩短47%,DeepSeek-V4的百万token推理计算量直接降为上一代的27%,现在英伟达在Vera Rubin平台里通过NVLink-C2C把FPGA和GPU连起来,GPU专门负责高吞吐的注意力计算,FPGA承接大上下文调度、前馈网络低延迟执行,再也不会出现之前GPU等数据调度空转的情况,昂贵的高端GPU算力利用率直接提升一个量级。
站在英伟达自身算力战略的层面拆解,FPGA帮它补齐了全栈异构生态的最后一块拼图
现在英伟达正式形成“GPU(通用训练)+ASIC(高效推理)+FPGA(灵活推理)”的三层算力架构,英伟达官方明确表示AI推理未来是“多芯片各司其职”,GPU为核心计算单元,FPGA承担连接、调度、实时处理和场景适配角色。围绕这个布局行业存在明显的观点分歧:
从竞争对手的市场反应视角来看,这次补位并没有直接抢现有玩家的蛋糕,反而打开了增量空间
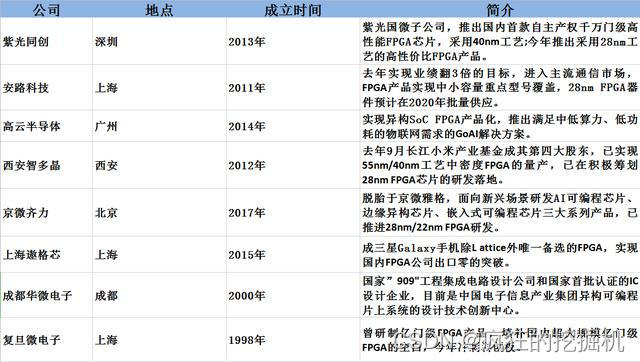
AMD的Instinct MI300系列在硬件性能上已经缩小了和英伟达GPU的差距,但至今没有推出完整的全栈异构推理方案,客户如果想要落地边缘低延迟场景,就得自己采购第三方FPGA做适配,开发成本会高出数倍;国内FPGA厂商如复旦微电、安路科技在中低端市场的本土化服务、成本优势依然稳固,英伟达的FPGA策略从来不是下沉去抢工业控制的低端存量市场,而是通过和CUDA生态打通,把大量原本GPU根本无法覆盖的场景激活为新增量市场。
整体来看,英伟达推出FPGA的动作,从头到尾都没有动摇GPU在其算力体系里的核心地位,反而在多个维度给GPU做了“放大式补位”:之前因为功耗、延迟、开发成本限制,GPU根本触达不到的海量边缘推理、低延迟智能体、快速算法迭代场景,现在通过FPGA作为协处理的桥梁全部可以落地,相当于英伟达把AI推理市场的整体边界往外扩了一大圈。
最终的结果不是FPGA抢了GPU的饭碗,而是原本很多高价值的推理需求因为算力体系不完整没法落地,现在靠异构协同全部释放出来,进一步巩固英伟达在AI全栈算力市场的主导权。