时间:2026-05-24 来源:FPGA_UCY 关于我们 0
这盘AI算力的全球博弈棋局,当下的棋手已经全部亮明身份:守擂的英伟达手握CUDA生态和全球高端训练市场9成以上份额的绝对筹码,对面站着三大对手,分别是谷歌TPU、AMD MI350为代表的云厂商自研ASIC阵营,华为昇腾领衔的国产替代芯片队伍,还有大量瞄准边缘低延迟场景的垂直算力玩家。
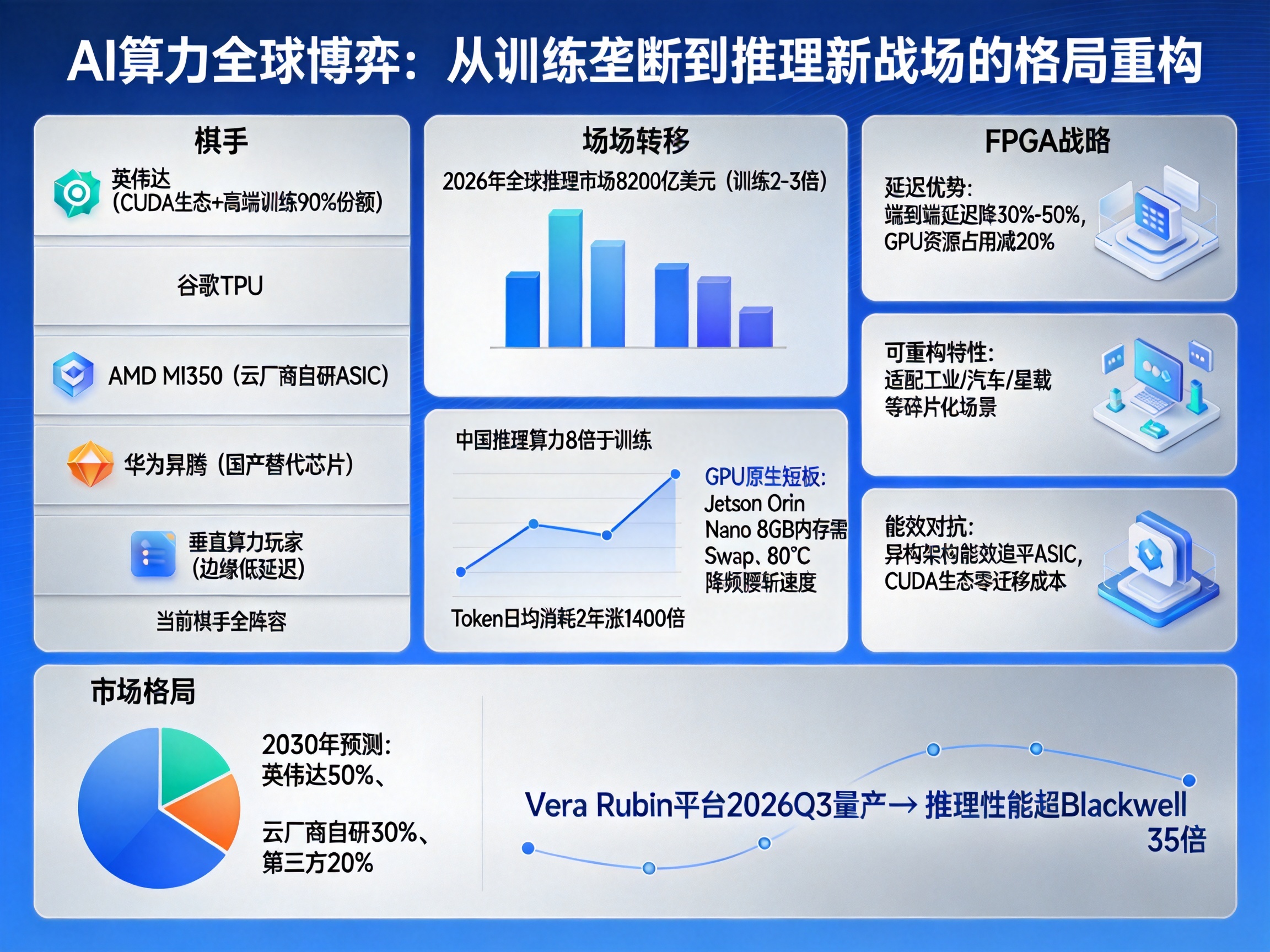
此前战场集中在AI训练环节,英伟达几乎已经锁死胜势,但随着算力需求彻底向推理转移,原有棋盘规则完全改写,黄仁勋主动把FPGA放到Vera Rubin平台的标准协处理单元位置,本质是在新战场落子抢占绝对先手,根本不是走一步看一步的临时应对。
训练垄断的舒适区,已经装不下推理市场的新战场
英伟达此前靠GPU+CUDA构建的护城河,在推理爆发的新周期里已经出现了明显缺口,老赛道的筹码根本带不到新牌桌上来。
如果英伟达继续死守GPU+CUDA的老舒适区,仅靠单芯片迭代根本挡不住对手的蚕食,推理市场至少一半的份额会在3年内流失,此前在训练端建立的垄断优势也会被逐步瓦解。
FPGA这步棋,根本不是多加一块芯片这么简单
黄仁勋主推FPGA的真实意图,完全跳出了普通硬件堆叠的逻辑,是从底层重构推理时代的算力规则:
第一,直接补齐GPU的效率短板。FPGA端到端延迟比纯GPU方案缩短30%-50%,把数据预处理、格式转换、轻量级推理这类低时延任务全部承接,能减少GPU集群20%以上的主算力资源占用,让昂贵的GPU彻底从杂活里解放出来,全部投入高吞吐的核心计算任务。
第二,用可重构特性接住所有碎片化场景。FPGA“极致可重构”的属性刚好适配推理场景的多元需求,不用针对工业、汽车、星载这类不同场景单独定制ASIC芯片,靠动态算子重构就能跟上AI算法的快速迭代,直接把GPU覆盖不到的边缘实时计算场景全部纳入英伟达的算力版图。
第三,直接消解对手的核心优势。之前ASIC玩家最大的筹码就是“能效比GPU更高”,现在英伟达用“GPU高吞吐+FPGA低延迟”的异构架构,整体能效水平直接追上专用ASIC,同时用户完全不用离开自己熟悉的CUDA生态,迁移成本几乎为零,直接把ASIC路线的差异化优势打没了大半。
当前局面下,对手的后手已经远少于英伟达
这步棋落子之后,市场各方的处境已经发生明确反转,英伟达反而把压力全部甩给了挑战者:
此前云厂商花几十亿自研ASIC的核心逻辑,就是靠专用硬件降低推理成本,但ASIC架构固定,只要大模型算法迭代一次,之前投入的全部硬件就可能面临过时淘汰的风险。而英伟达的异构方案,既兼顾了成本效率,又保留了适配算法迭代的灵活性,相当于把自研ASIC的最大风险点给直接抹除了。
摩根士丹利预测的2030年AI芯片市场“英伟达50%、云厂商自研30%、第三方厂商20%”的格局,现在已经开始向英伟达倾斜——挑战者如果继续走纯ASIC路线,性价比优势会被持续压缩;如果想跟进异构方案,复刻英伟达“CPU+GPU+FPGA”全栈协同的体系,至少需要3-5年的研发周期,时间窗口完全不在对手这边。
接下来的棋局走向已经非常清晰
英伟达推出FPGA这步棋之后,接下来的走法几乎没有悬念:
首先随着Vera Rubin平台在2026年Q3量产出货,这套异构算力方案会快速渗透此前GPU覆盖不到的边缘计算、工业智能体、太空算力等细分场景,英伟达在推理市场的份额会迎来新一轮跳涨,黄仁勋放话Rubin架构推理性能比Blackwell高35倍的目标,很大一部分增量来自FPGA和GPU的协同提效。
其次英伟达会快速把FPGA的开发工具链全部接入CUDA生态,把之前FPGA开发门槛高、生态不完善的痛点彻底解决,进一步拉高异构算力的行业标准。所有对手接下来不管走什么路线,都不得不面对英伟达把全栈算力标准握在手里的现实,这盘从训练打到推理的算力博弈,英伟达的先手优势已经越握越牢。