时间:2026-03-15 来源:FPGA_UCY 关于我们 0
AI芯片(又称AI加速器)的核心使命是高效支撑人工智能算法(尤其是深度学习、机器学习)的运算,解决CPU在AI任务中并行算力不足、能效比低的痛点。目前主流的AI芯片技术架构主要分为三类:GPU(图形处理器)、FPGA(现场可编程门阵列)、ASIC(专用集成电路)。三者在设计理念、性能特性、应用场景上差异显著,分别适配不同层级、不同需求的AI任务,共同构成了AI算力生态的核心支撑。以下从各架构的核心细节展开,结合实际案例与未来趋势,全面解析三者的区别与价值。
一、GPU(Graphics Processing Unit,图形处理器)1. 技术概述
GPU最初设计用于图形渲染,核心是解决图像像素的并行计算问题(如3D场景渲染、光影效果处理)。随着AI浪潮兴起,人们发现其“多核心并行计算”的架构的天然适配深度学习中“海量数据并行运算”的需求(如神经网络的矩阵乘法、卷积运算),因此被快速改造为通用AI算力芯片,成为当前AI训练与推理的主流硬件。其核心本质是“并行计算架构”,采用SIMT(单指令多线程)设计,单条指令可驱动多个线程同步执行,尤其适配“计算密集型+数据并行型”任务,就像“千人团队”,擅长同时处理海量重复运算,与CPU“百人专家团”侧重串行复杂逻辑的定位形成互补。
GPU的核心组成包括流处理器(SP)、流多处理器(SM)、高带宽显存(VRAM),以及CUDA(NVIDIA专属)、OpenCL(跨平台)等通用计算接口,这些组件共同保障了并行算力的高效输出,让GPU突破图形处理局限,成为AI算力的核心载体。
2. 核心特点3. 应用场景及案例(每个场景1个通俗案例)场景1:AI模型训练(核心场景)
核心需求:处理海量训练数据(如图片、文本),完成神经网络参数迭代,需要极强的并行算力和高带宽显存,支撑模型快速收敛。GPU是目前AI训练的“算力基石”,几乎所有主流AI大模型的训练都依赖GPU集群。
案例:ChatGPT模型训练。OpenAI在训练ChatGPT(GPT-3.5/GPT-4)时,采用了由数千块NVIDIA A100 GPU组成的集群。A100拥有6912个CUDA核心,显存带宽达1935GB/s,可高效处理万亿级参数模型的矩阵运算,原本需要数年的训练任务,通过GPU集群并行计算,可缩短至数月甚至数周,大幅提升模型研发效率。类似的,Stable Diffusion等生成式AI模型的训练,也完全依赖GPU集群的并行算力支撑。
场景2:AI模型推理(云端/边缘端)
核心需求:将训练好的AI模型部署到实际场景,接收实时输入数据(如用户提问、监控画面),快速输出推理结果,要求低延迟、高吞吐量,部分场景需兼顾功耗。GPU可适配云端大规模推理和边缘端中高算力推理场景。
案例:抖音智能推荐系统(云端推理)。抖音每日产生数十亿条用户行为数据(点赞、评论、浏览),需要实时对每一位用户进行兴趣推荐,背后依赖海量AI推理任务。字节跳动采用NVIDIA T4 GPU部署推荐模型推理集群,T4 GPU针对AI推理优化,单卡可同时处理数千路推理请求,延迟控制在毫秒级,确保用户刷到的每一条内容都是实时适配其兴趣的,支撑起抖音庞大的推荐生态。
场景3:计算机视觉(CV)场景(中高算力需求)
核心需求:处理图像、视频数据(如目标检测、图像分割、人脸识别),涉及大量卷积运算和特征提取,需要并行算力支撑,同时要求一定的灵活性(适配不同CV算法)。
案例:城市监控智能分析系统。某城市在交通路口、商圈部署了数千个监控摄像头,需要实时检测闯红灯、违章停车、人员聚集等异常情况。该系统采用NVIDIA Jetson AGX Orin GPU(边缘端GPU)部署目标检测模型(如YOLOv8),每个GPU可同时处理8-16路监控视频,实时输出异常预警,无需将所有视频数据上传至云端,既降低了网络带宽压力,又保证了检测延迟(≤100ms),实现城市安防的智能化管控。
场景4:科学计算与AI融合场景
核心需求:将AI算法与传统科学计算结合,加速复杂计算任务,如气象预测、基因测序、流体力学模拟等,需要海量并行算力支撑,同时适配多样化的计算模型。
案例:气象灾害预测。某气象部门采用GPU集群结合AI模型,处理全球气象卫星采集的海量数据(温度、气压、湿度等),通过深度学习模型预测台风、暴雨等灾害的路径和强度。原本需要数月的计算任务,通过GPU并行计算可缩短至数天甚至数小时,大幅提升气象预测的及时性和准确性,为防灾减灾提供决策支撑。
4. 未来展望二、FPGA(Field Programmable Gate Array,现场可编程门阵列)1. 技术概述
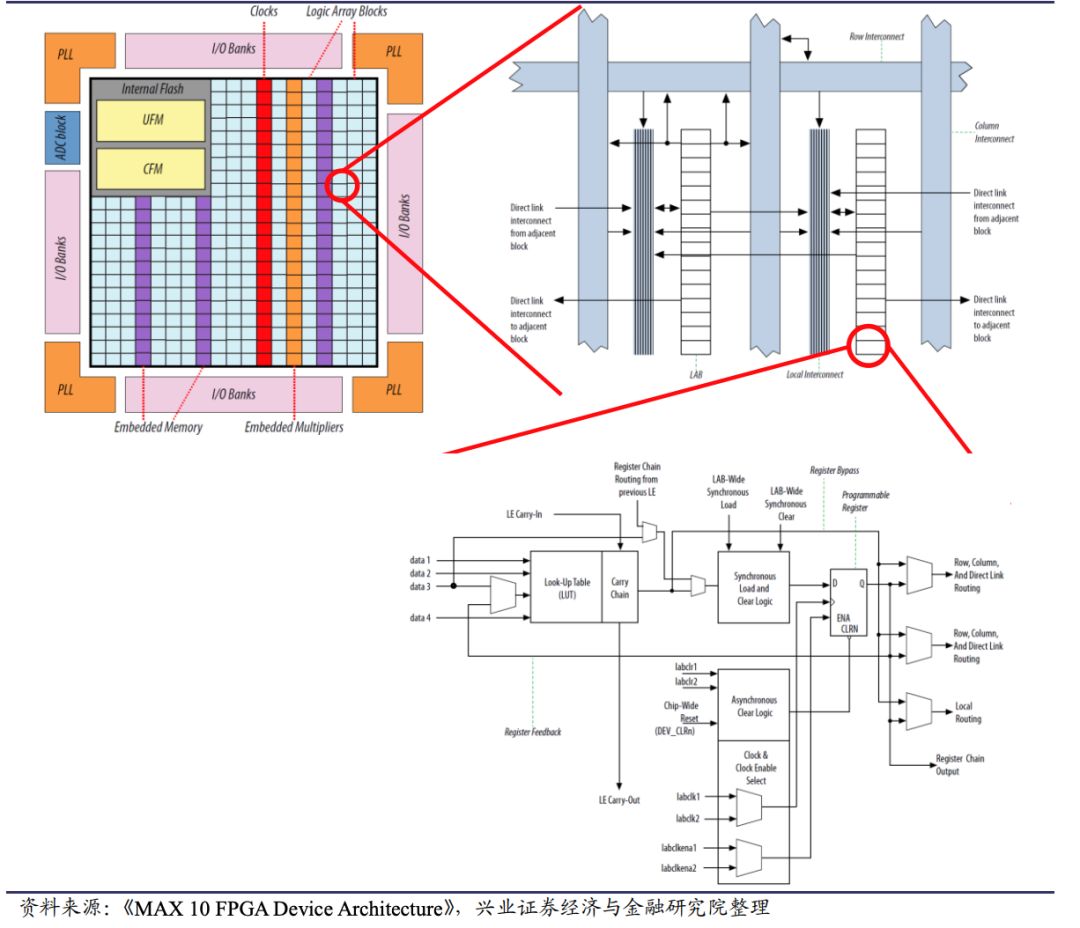
FPGA是一种“可编程硬件”,其核心是由大量可配置的逻辑单元(CLB)、输入输出单元(IOB)、互联资源组成,用户可通过硬件描述语言(HDL,如Verilog、VHDL)对其进行编程,定义逻辑单元的连接方式和运算逻辑,实现特定的功能。与GPU的“通用并行”、ASIC的“固定功能”不同,FPGA的核心优势是“可编程性+硬件级并行”——既具备硬件的高算力、低延迟特性,又具备软件的灵活可修改性,可根据AI算法的迭代快速调整硬件逻辑,无需重新设计芯片。
FPGA的本质是“可重构硬件”,设计人员可在芯片部署后根据需求重新编程或配置数字逻辑,这一特性使其在快速变化的技术环境中具备天然优势,尤其适合算法迭代快、场景需求多变的AI场景,成为算法探索期和标准未定阶段的理想选择。
2. 核心特点3. 应用场景及案例(每个场景1个通俗案例)场景1:AI数据预处理(数据中心/边缘端)
核心需求:在AI模型训练/推理前,对原始数据(如图片去噪、文本格式化、传感器数据滤波)进行快速处理,去除冗余信息、统一数据格式,缓解后端算力单元(GPU/CPU)的压力,要求低延迟、高吞吐量,且算法可迭代。FPGA作为数据预处理的“第一道关卡”,能高效完成数据清洗、格式转换等任务,缓解内存和I/O瓶颈。
案例:数据中心AI训练数据预处理。某互联网企业的AI训练平台,每日接收数百万张图片训练数据,需要先进行去噪、尺寸归一化、灰度化等预处理操作。该平台采用Xilinx Alveo U280 FPGA部署预处理算法,FPGA可并行处理数千张图片,预处理延迟仅为50微秒/张,相较于CPU处理速度提升10倍,相较于GPU处理功耗降低70%,大幅提升了AI训练的整体效率,避免了“垃圾进,垃圾出”的问题。
场景2:边缘端AI推理(高实时性、低功耗需求)
核心需求:部署在嵌入式设备、工业终端等边缘场景,处理实时数据(如工业传感器数据、自动驾驶感知数据),要求低延迟、低功耗、小体积,且算法可能随场景需求迭代。FPGA的低功耗、高实时性和可编程性,使其成为边缘AI的“算力核心”。
案例:工业机器人视觉导航。某工厂的工业机器人需要通过摄像头实时识别生产线的工件位置,完成精准抓取和组装,要求识别延迟≤50微秒,功耗≤10W,且需根据工件类型的变化调整识别算法。该机器人采用Intel Stratix 10 FPGA部署目标识别模型,FPGA可实时处理摄像头采集的图像数据,快速输出工件坐标,延迟控制在30微秒,功耗仅8W,同时可通过重新编程适配新的工件识别算法,无需更换机器人核心硬件,降低了设备升级成本。
场景3:通信领域AI加速(5G/6G场景)
核心需求:在5G/6G基站中,处理海量通信数据(如信号调制解调、波束成形、AI信号优化),要求低延迟、高可靠性,且通信标准可能随技术迭代调整。FPGA的可编程性使其能适配不断变化的协议要求,成为通信基础设施部署初期的首选。
案例:5G基站AI波束成形加速。某运营商的5G基站需要通过AI算法优化波束成形,提升信号覆盖范围和通信质量,同时需适配5G协议的迭代升级。该基站采用AMD(赛灵思)Versal FPGA部署AI波束成形算法,FPGA可实时处理基站接收的信号数据,动态调整波束方向,提升信号强度,且当5G协议升级时,可通过重新编程更新算法,无需更换基站核心芯片,大幅降低了基站升级成本,同时保障了通信的低延迟和高可靠性。
场景4:医疗影像AI处理(高精度、低延迟需求)
核心需求:处理医疗影像(如CT、MRI、视网膜扫描),完成病灶检测、图像重建等任务,要求高精度、低延迟,且算法需根据医学研究进展不断优化。FPGA的并行算力和可编程性,能高效处理海量模拟数据并进行复杂矩阵运算,适配医疗影像处理的核心需求。
案例:CT影像快速重建。某医院的CT设备需要将采集的断层扫描数据快速重建为三维影像,供医生诊断病灶,要求重建延迟≤1秒,且需支持多种重建算法(如滤波反投影算法、迭代重建算法)。该设备采用Xilinx VU9P FPGA部署影像重建AI算法,FPGA可并行处理CT扫描数据,将重建延迟控制在800毫秒,相较于GPU处理延迟降低60%,同时可通过重新编程切换不同的重建算法,适配不同部位、不同精度的诊断需求,帮助医生更快发现早期病变。
4. 未来展望三、ASIC(Application-Specific Integrated Circuit,专用集成电路)1. 技术概述
ASIC是为某一特定应用场景、特定AI算法或单一任务“量身定制”的集成电路,其核心逻辑是“功能固化”——芯片设计阶段就完全适配某一具体任务(如特定深度学习模型的推理、比特币挖矿),摒弃所有冗余的计算模块,仅保留完成该任务所需的逻辑单元和运算电路。与GPU的通用性、FPGA的可编程性不同,ASIC一旦设计、流片完成,其功能便固定不变,无法修改,但能实现极致的算力、能效比和成本控制,是AI场景中“极致优化”的算力解决方案。
ASIC遵循DSA(领域专用架构)理念,实现“场景需求→架构设计→性能优化”的闭环,其发展历程从早期的消费电子辅助芯片,逐步升级为支撑数字经济核心场景的“算力核心”,尤其在AI大模型、自动驾驶等对算力密度、功耗控制有极致要求的场景中,优势极为突出。
2. 核心特点3. 应用场景及案例(每个场景1个通俗案例)场景1:AI大模型推理(大规模部署场景)
核心需求:将训练好的大型语言模型(LLM)、生成式AI模型部署到大规模集群,为海量用户提供推理服务(如ChatGPT对话、AI绘画),要求极高的算力、极低的功耗和延迟,且任务单一(仅适配特定模型推理)。ASIC的极致算力和能效比,使其成为大规模AI推理集群的首选。
案例:谷歌TPU用于Gemini大模型推理。谷歌为其自研的Gemini大模型(万亿参数级)定制了TPU(张量处理单元),这是一款专为AI大模型推理设计的ASIC芯片。TPU v4单芯片算力达1.1 Exa-FLOPS,能效比是NVIDIA A100 GPU的3倍,谷歌部署了由数万个TPU组成的集群,支撑Gemini大模型的全球推理服务,可同时响应数百万用户的对话请求,延迟控制在100毫秒以内,且集群整体功耗仅为同等算力GPU集群的1/3,大幅降低了数据中心的运营成本。截至2026年,谷歌已推出第七代TPU(Ironwood),成为首款专为AI推理时代设计的TPU,进一步优化了推理延迟和能效比。
场景2:车载AI(自动驾驶场景)
核心需求:自动驾驶汽车需要实时处理摄像头、激光雷达等传感器的海量数据(如目标检测、路径规划、决策控制),要求极高的实时性(延迟≤10毫秒)、极低的功耗(适配车载电源),且任务固定(仅适配自动驾驶相关算法),ASIC的特性完美适配该场景。
案例:特斯拉FSD芯片(自动驾驶ASIC)。特斯拉为其自动驾驶系统(FSD)定制了专属ASIC芯片,该芯片专为自动驾驶的目标检测、路径规划算法设计,集成了两个AI运算核心,单芯片算力达144 TOPS,功耗仅25W。FSD芯片可实时处理车载8个摄像头、1个激光雷达采集的数据,快速完成障碍物识别、车道线检测、路径规划等任务,延迟控制在5毫秒以内,支撑特斯拉自动驾驶系统实现L4级别的自主行驶,且大规模量产後,单片成本仅为同等算力GPU的1/5,大幅降低了自动驾驶汽车的硬件成本。
场景3:边缘端微型AI设备(极低功耗需求)
核心需求:部署在微型嵌入式设备(如智能手表、智能耳机、微型传感器),完成简单的AI任务(如心率检测、语音唤醒、手势识别),要求极低的功耗(毫瓦级)、极小的体积,且任务单一,无需算法迭代。ASIC的低功耗、小体积优势,使其成为这类场景的唯一选择。
案例:苹果Watch心率检测ASIC芯片。苹果Watch的心率检测功能,采用了苹果自研的ASIC芯片,该芯片专为心率检测算法定制,仅保留心率数据采集、分析所需的逻辑单元,功耗仅为5毫瓦(约为GPU的1/1000),体积不足1平方毫米。该ASIC芯片可实时采集用户的心率数据,快速分析是否存在异常,无需依赖手机或云端算力,且续航时间可达18小时,完美适配智能手表的低功耗、小体积需求。类似的,苹果Siri语音唤醒功能,也采用了专属ASIC芯片,实现低功耗下的实时语音识别。
场景4:专用AI计算场景(单一任务大规模部署)
核心需求:某一单一AI任务需要大规模部署,任务逻辑固定,对算力和能效比要求极高,如AI安防监控、AI语音转写、加密货币挖矿(国内已禁止)等。ASIC可通过大规模量产实现成本优化,同时提供极致的算力支撑。
案例:阿里AI语音转写ASIC芯片。阿里为其智能客服系统的语音转写任务,定制了专属ASIC芯片,该芯片专为语音转写算法(如CNN-LSTM模型)设计,单芯片可同时处理100路语音转写任务,延迟≤500毫秒,功耗仅10W,能效比是GPU的8倍。阿里在全国部署了数千块该ASIC芯片,支撑智能客服系统的语音转写服务,每日处理数百万通客服电话,将语音转化为文本,大幅提升了客服效率,同时降低了数据中心的功耗和运营成本。
4. 未来展望四、GPU、FPGA、ASIC三大架构核心对比(汇总表)
对比维度
GPU
FPGA
ASIC
核心定位
通用并行算力,适配多场景AI任务
可编程硬件加速,适配算法迭代场景
专用定制算力,适配单一固定任务
并行算力
极高(数千~数万个核心)
中等(优于CPU,低于GPU)
极致(GPU的10~100倍)
延迟表现
中等(毫秒级)
极低(微秒级)
极低(微秒级,甚至纳秒级)
能效比
中等(优于CPU,低于FPGA/ASIC)
高(GPU的5~10倍)
极高(GPU的10~20倍)
灵活性
极高(适配多种算法,可灵活切换)
中等(可重新编程,适配算法迭代)
极低(功能固定,无法修改)
开发门槛
低(软件生态成熟,上手容易)
高(需掌握硬件描述语言)
极高(需芯片设计、流片能力)
成本(大规模)
中等
较高
极低(摊薄研发成本后)
核心应用场景
AI训练、云端推理、CV中高算力场景
数据预处理、边缘端高实时推理、通信AI加速
大模型大规模推理、车载AI、微型边缘设备
代表产品
NVIDIA H100/A100、AMD MI300、华为昇腾910
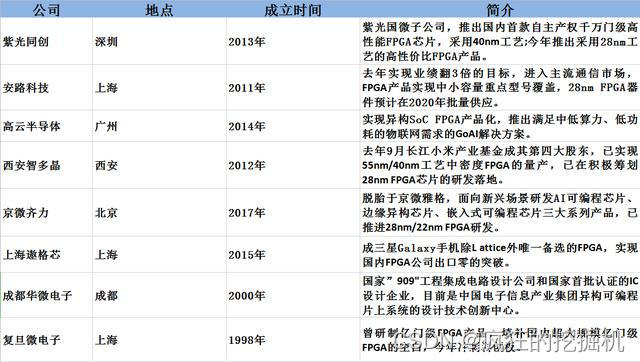
Xilinx Alveo、Intel Stratix、紫光国微FPGA
谷歌TPU、特斯拉FSD、苹果Siri芯片
五、整体总结
GPU、FPGA、ASIC三大AI芯片架构,没有绝对的“优劣”,而是根据AI任务的需求(算力、延迟、功耗、灵活性、成本)形成互补,共同支撑AI生态的发展:
未来,AI芯片的发展趋势将是“异构融合”——GPU、FPGA、ASIC与CPU协同工作,各自发挥优势,同时结合Chiplet、存算一体等新技术,进一步提升算力、降低功耗、缩短研发周期,适配更多细分AI场景。同时,国产化替代将成为重要方向,国内企业将在三大架构上持续突破,打破海外垄断,推动AI算力的自主可控。

上一篇:FPGA是什么(超级详细)
下一篇:fpga是什么