时间:2024-08-03 来源:网络搜集 关于我们 0
强化学习(RL)通过与环境交互的试错反馈来优化顺序决策问题。
虽然RL在允许大量试错的复杂电子游戏环境中实现了超越人类的决策能力(例如王者荣耀,Dota 2等),但很难在包含大量自然语言和视觉图像的现实复杂应用中落地,原因包括但不限于:数据获取困难、样本利用率低、多任务学习能力差、泛化性差、稀疏奖励等。
大语言模型(LLM),通过在海量数据集上的训练,展现了超强的多任务学习、通用世界知识目标规划以及推理能力。以ChatGPT为代表的LLM已经被广泛应用到各种现实领域中,包括但不限于:机器人、医疗、教育、法律等。
在此背景下,LLM可以提高强化学习在例如多任务学习、样本利用率、任务规划等方面的能力,帮助提高强化学习在复杂应用下的学习表现,例如自然语言指令跟随、谈判、自动驾驶等。
为此,来自香港中文大学(深圳)的团队调研了130余篇大语言模型及视觉-语言模型(VLM)在辅助强化学习(LLM-enhanced RL)方面的最新研究进展,形成了该领域的综述文章一篇,目前以预印版形式上传到arXiv网站,期望能为各位研究人员和工程人员提供一定的技术参考。

论文链接:https://arxiv.org/abs/2404.00282
该综述总结了LLM-enhanced RL的主要技术框架、特性以及四种主要技术路线;并分析了未来该方向的机会与挑战。
下面针对文章主要内容概括介绍,详细内容请参阅英文综述论文。
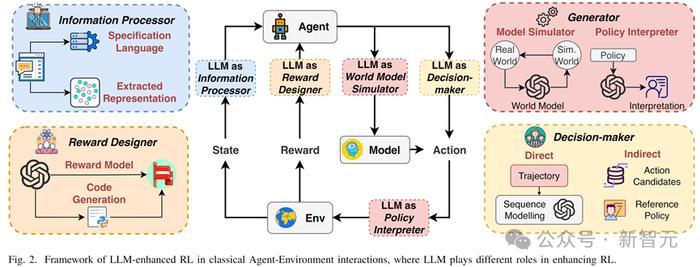
LLM-enhanced RL 框架
LLM-enhanced RL 定义:指利用已预训练、内含知识(knowledge-inherent)的AI模型的多模态(multi-modal)信息处理、生成、推理等能力来辅助RL范式的各种方法。
主要特性(Characteristics):
1. 多模态信息理解(multi-modal information understanding)
2. 多任务学习和泛化(multi-task learning and generalization)
3. 样本利用率的提高(improved sample efficiency)
4. 长期轨迹规划能力(long-horizon handling)
5. 奖励信号生成能力(reward signal generation)
LLM的主要角色分类
1. 信息处理者(information processor):包括1)文字和视觉表征提取;2)复杂自然语言翻译。
2. 奖励设计者(reward designer):即隐式奖励模型与显式奖励模型(奖励函数代码生成)。
3. 决策者(decision-maker):包含直接决策与间接辅助决策两种。
4. 生成者(generator):即1)世界模型中的轨迹生成和2)强化学习中的策略(行为)解释生成。
LLM 作为信息处理者(LLM as Information Processor)
在富含文字和视觉信息的环境中,深度强化学习(deep RL)通常需要同时学习多模态的信息处理和决策控制策略,因此学习效率大幅下降。且不规范、多变的自然语言和视觉信息往往会对代理学习产生大量干扰。
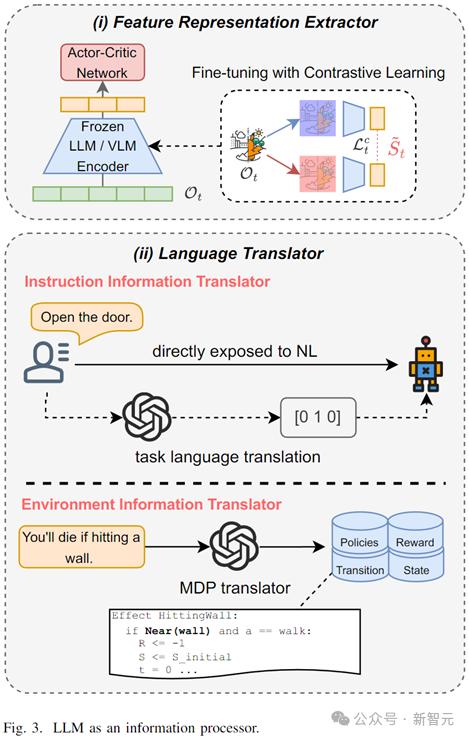
LLM在此情况下可以(1)有效表征提取,加速下游神经网络学习;(2)自然语言翻译,将不规范、冗余复杂的自然语言指令和环境信息翻译为规范的任务语言,帮助代理过滤无效信息。
LLM 作为奖励设计者(LLM as Reward Designer)
奖励函数设计和有效奖励信号生成一直是强化学习在复杂任务或者稀疏奖励环境下的两大难题。
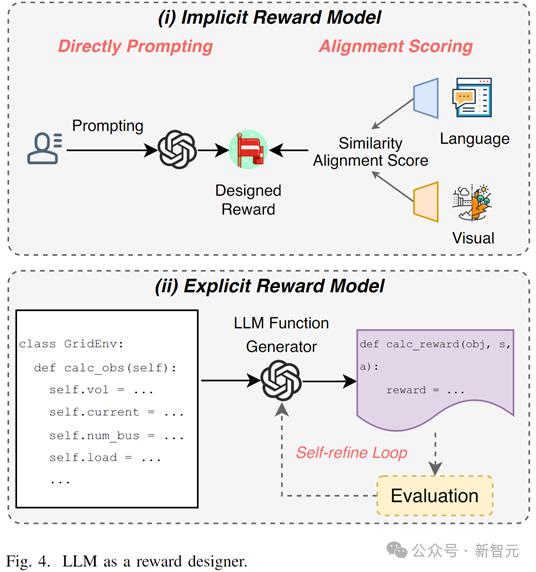
大模型可以通过以下两种方式缓解该问题
1. 隐式奖励函数设计:利用上下文理解能力、推理能力和知识,通过任务prompt或文字-视觉对齐的方式生成奖励
2. 显式奖励函数设计:通过输入环境规范信息,LLM生成可执行奖励函数代码(例如 Python 等),显式地逻辑计算奖励函数的各个部分,且可以根据评估自主修正。
LLM 作为决策者(LLM as Decision-Maker)
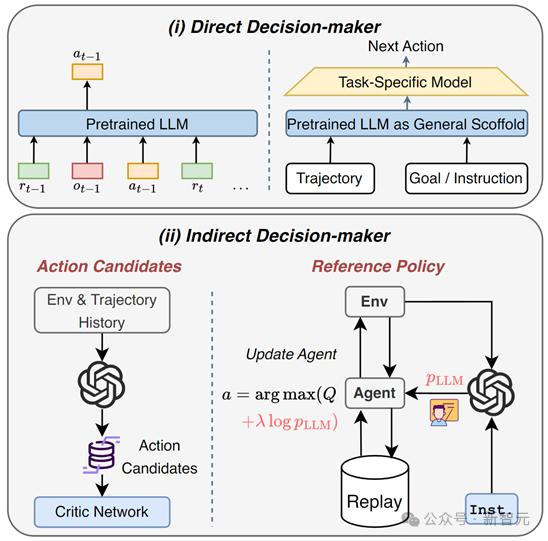
在决策问题中,大模型可以作为:
1. 直接决策者:Decision Transformer在离线强化学习中展现了巨大的潜力,大语言模型可视作增强版的大型预训练Transformer模型,利用本身强大的时序建模能力和自然语言理解能力解决离线强化学习的长期决策问题。
2. 间接决策者:作为一个指导者,结合预训练专家知识和任务理解能力,生成动作候选(action candidates),缩小动作选择范围;或者生成参考策略(reference policy)指导RL策略更新。
LLM 作为生成者(LLM as Generator)
在基于模型的强化学习(model-based RL)中,LLM可以作为多模态世界模型(world model),结合自身知识和建模能力来生成高质量长期轨迹或者学习世界状态转移表征。
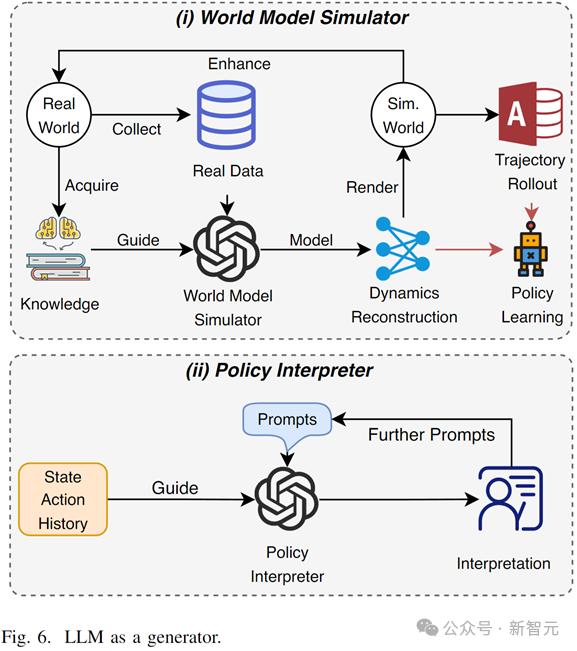
在可解释强化学习中,大模型可以通过理解轨迹、环境与任务,根据prompt自动生成代理的自然语言行为解释,增加用户在调用、调优RL模型时的理解。
讨论(Discussion)
LLM-enhanced RL的未来潜在应用包括但不限于:
1. 机器人:利用多模态理解能力和推理能力,LLM-enhanced RL可以提升人-机器的交互效率;帮助机器人理解人类需求逻辑;提高任务决策和规划能力。
2. 自动驾驶:自动驾驶使用强化学习做复杂动态场景下的决策问题,涉及多传感器数据与道路规范、行人举止等。大模型可以帮助强化学习处理多模态信息以及设计综合奖励函数,例如安全、效率、乘客舒适度等
3. 电力系统能量管理:在能量系统中,运营者或者用户使用强化学习来高效管理多种能力的使用、转换和存储等,其中涉及高不确定性的可再生能源。大模型可以帮助设计多目标函数与提高样本利用效率。
LLM-enhanced方向的潜在机会:
1. 在强化学习方面:目前的工作都集中在通用强化学习,而针对特定强化学习分支的工作较少,包括多代理强化学习、安全强化学习、迁移强化学习和可解释强化学习等。
2. 在大模型方面:目前的工作大部分仅仅是使用prompt技术,而检索增强生成(RAG)技术和API、工具调用能力可以显著提高LLM在特定情况下的表现。
LLM-enhanced RL 的挑战:
1. 对大模型的能力依赖:大模型的能力决定了强化学习代理学习到的策略,大模型固有的偏见、幻觉等问题也会影响代理的能力。
2. 交互效率:目前大模型的计算开销较大、交互效率慢,在在线强化学习中会影响代理与环境的交互速度。
3. 道德、伦理问题:实际人-机器的应用中,大模型的道德、伦理等问题需要被认真考虑。
总结
该综述文章系统总结了大模型在辅助强化学习方面的最近研究进展,定义了LLM-enhanced RL这样一类方法,并总结了大模型在其中的四种主要角色及其方法,最后讨论了未来的潜在应用、机会与挑战,希望能给未来该方向的研究者一定启发。
1. 信息处理者:大模型为强化学习代理提取观测表征和规范语言,提高样本利用效率。
2. 奖励设计者:在复杂或无法量化的任务中,大模型利用知识和推理能力设计复杂奖励函数和生成奖励信号。
3. 决策者:大模型直接生成动作或间接生成动作建议,提高强化学习探索效率。
4. 生成者:大模型被用于:(1)作为高保真多模态世界模型减少现实世界学习成本及(2)生成代理行为的自然语言解释。